Implementing Reproducible Visualizations
Application of coloring book technique in a reproducible ggplot2 system
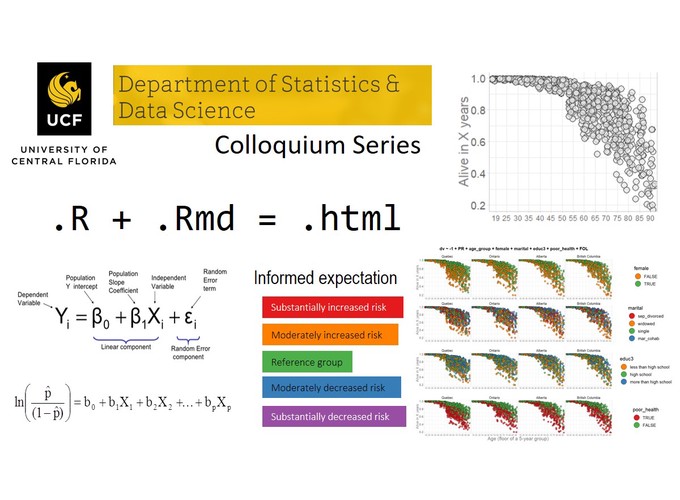
Visualising results of statistical modeling is a key component of data science workflow. Statistical graphs often is the best means to explain and promote research findings. However,in order to find that one graph that tells the story worth sharing, we sometimes have to try out and sift through many data visualizations. How should we approach such a task? What can we do to make it easier from both production and evaluation perspectives? This talk will demonstrate a reproducible graphing system designed for the IPDLN-2018 hackathon.
The system evaluates synthetic socioeconomic and mortality data with logistic regression. The data was prepared for the hackathon by Statistic Canada and represents Canadian population. First, I will introduce a visualisation technique that uses color to create a meaningful expectations from the results of a logistic regression. Then I will discuss the workflow of the project that implements this graphing system ( github.com/andkov/ipdln-2018-hackathon ). I will conclude by building the case to prefer reproducible workflows with version control over computational notebooks (e.g. Jupyter, R Notebook).